

-


大数据云计算
站-
热门城市 全国站>
-
其他省市
-
-

 400-636-0069
400-636-0069
 小标
2019-01-14
来源 :
阅读 763
评论 0
小标
2019-01-14
来源 :
阅读 763
评论 0
摘要:本文主要向大家介绍了【云计算】kafka简要概述,通过具体的内容向大家展现,希望对大家学习云计算有所帮助。
本文主要向大家介绍了【云计算】kafka简要概述,通过具体的内容向大家展现,希望对大家学习云计算有所帮助。
解决问题
生产者种类多,数据格式不同,数据源众多,消费者种类多:使用生产者和消费者模式进行解耦 消费者无法依据自身处理情况轮询拉取数据:提供数据持久化,适配多个消费者 消息系统无法横向扩展:系统随流量进行很想扩展,使用消息批次加压缩的模式提高消息传输效率
概念
主题
通过主题对消息进行分类 配置项
partition:分区数 设置日志保留的时间、每个分区保留的日志大小 每个日志片段的大小,多长时间关闭一个片段 单个消息的大小
分区
一个主题被分割成了多个分区 消息以追加的方式写入分区,先进先出的队列模式 分区可以再不同的服务器上 一个分区可以分配到一个或者多个broker上,一个为分区首领,其他为复制(提高可靠性) 首领副本负责和生产者消费者进行交互,而副本从首领处拷贝保持同步
消息
包含:主题、分区、消息建、消息
生产者
如果没有消息键生产者将消息均匀的分配到不同的分区上 如果有消息键,同一个消息键的消息写入相同的分区,用户可以自定义分区器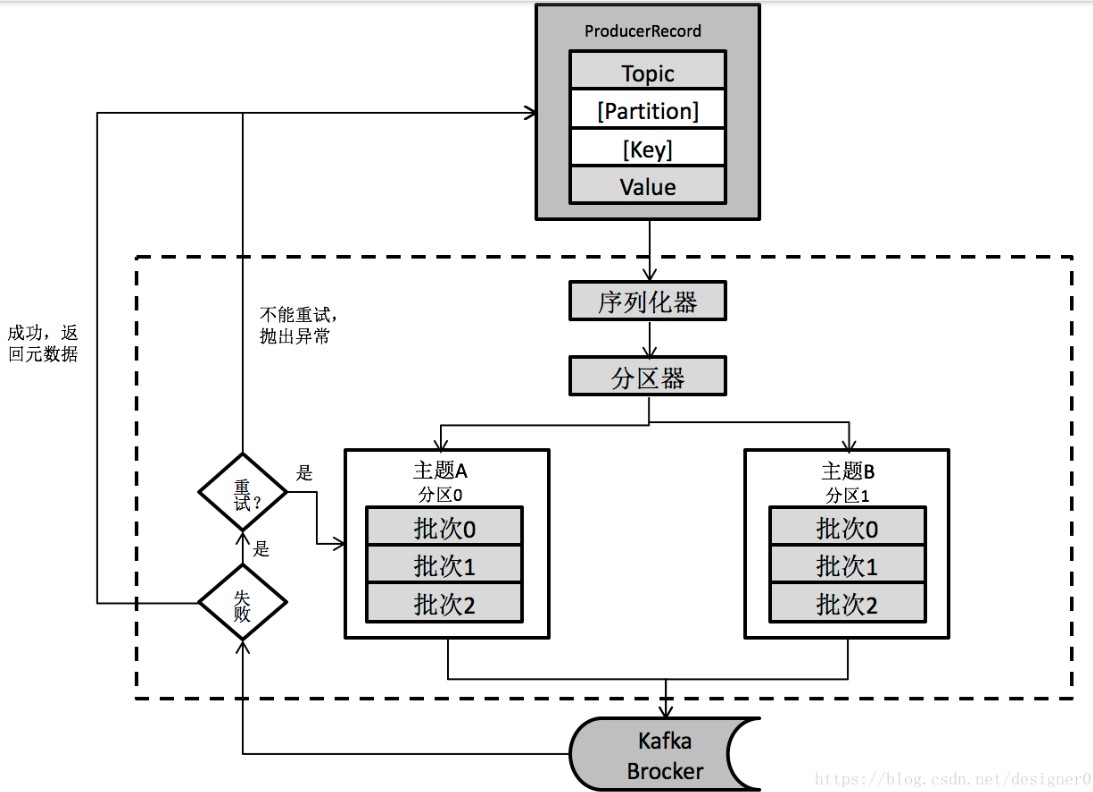
配置项
配置broker的地址 键、值的序列化类 缓冲区大小 生产者在收到服务器响应前可以发送多少个消息(消息保序的关键,一次只发一个消息给broker,确保每个消息都能收到)
消费者
为每一个分区维护一个offset,记录读取消息的位置,位置记录在zk中 通过订阅主题,主动拉取消息offset 配置项:
是否自动提交 指定分区分配策略 在offset无效时读取的策略
再均衡监听器
通过监听,在发生在均衡的时候可以关闭一些资源(数据库),提交offset
消费者组群
包含一个或者多个消费者 群组保证每个主题分区只能被一个消费者消费 每个群组会消费每个主题的所有分区
broker
kafka服务端,用来存放生产者产生的数据,为数据设置偏移量 响应消费者读取数据的请求 broker的数据不会立刻消失
配置主题保留一段时间或者一定文件大小的数据 配置主题仅保留最后一个带有特定键的消息 配置:
id:集群中唯一的id port:kafka的port zk地址 log.dirs:存放日志的位置 设置初始化时的线程数:和启动速度有关 创建主题的时机
kafka集群
第一步选举出一个broker作为控制器
启动步骤
在zk上注册一个自己的节点,同时监听Zookeeper的/brokers/ids路径下broker的变化情况。删除时会在Zookeeper的/brokers/ids中删除节点,但是自己的broker id节点不会删除 在zk上/controller尝试创建临时节点,如果成功成为控制器,否则监听控制器节点的变化
生产者分区和消费者群组
一个主题的分区数量<消费者群组的消费者数量,有消费者空闲 一个主题的分区数量=消费者群组的消费者数量,一个消费者对应一个分区 一个主题的分区数量>消费者群组的消费者数量,多个分区的消息在一个消费者上处理
分区偏移量
消息消费后向特定的topic发送消息,将offset保存在zk中。如果发生分区在均衡,这样可以用kafka上获取到offset,使得消费者无状态 可以通过seek方法指定偏移量和分区
本文由职坐标整理并发布,希望对同学们有所帮助。了解更多详情请关注职坐标大数据云计算大数据安全频道!
 喜欢 | 0
喜欢 | 0
 不喜欢 | 0
不喜欢 | 0


您输入的评论内容中包含违禁敏感词
我知道了

请输入正确的手机号码
请输入正确的验证码
您今天的短信下发次数太多了,明天再试试吧!
我们会在第一时间安排职业规划师联系您!
您也可以联系我们的职业规划师咨询:

版权所有 职坐标-一站式IT培训就业服务领导者 沪ICP备13042190号-4
上海海同信息科技有限公司 Copyright ©2015 www.zhizuobiao.com,All Rights Reserved.
 沪公网安备 31011502005948号
沪公网安备 31011502005948号






 索取资料
索取资料

 答疑解惑
答疑解惑

 技术交流
技术交流

 职业测评
职业测评

 面试技巧
面试技巧

 高薪秘笈
高薪秘笈




